
机器学习彩图知识点-A系列
最近看到国外一位大神对机器学习知识点绘制的彩图,通过图解的形式来解释一个知识点,比如过拟合、auc、boosting算法等,非常的形象👍,比如:
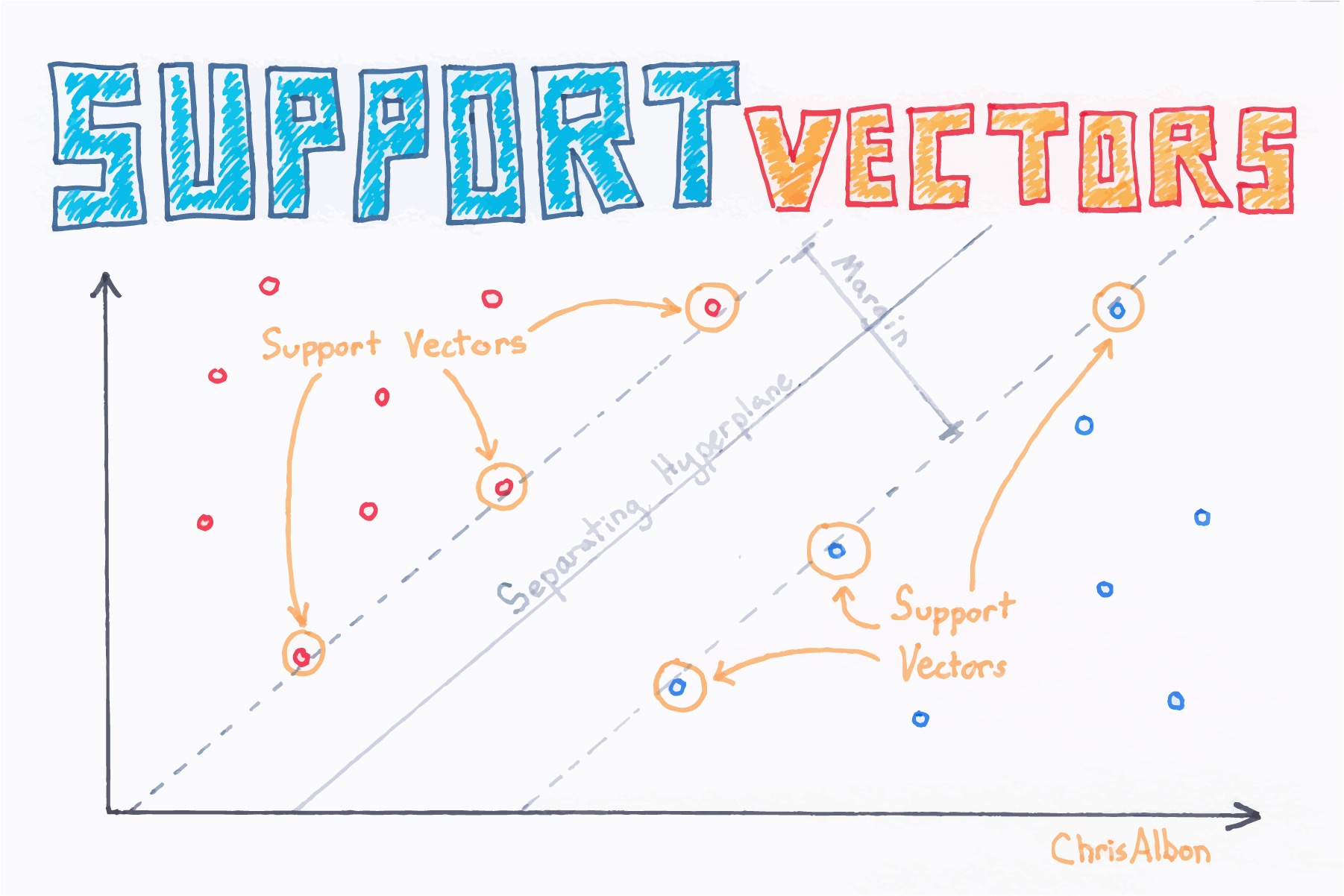
支持向量机
L2正则化过程

原地址:https://machinelearningflashcards.com/,作者:Chris Albon
全图
先看一个比较全面的图形:这里面有Dropout、TF-IDF、SVC等

A系列
今天分享A系列的内容。
AIC-赤池信息量准则
赤池信息量准则,即Akaike information criterion、简称AIC,是衡量统计模型拟合优良性的一种标准,是由日本统计学家赤池弘次创立和发展的。赤池信息量准则建立在熵的概念基础上。
AIC越小,模型越好,通常选择AIC最小的模型
- n:观测值
- $\hat \sigma ^2$:样本方差
- d:特征值
- RSS:残差平方和

Accuracy-准确率
表示在检测样本中实际值和预测值相等的占比

Adaboost算法
AdaBoost全称为Adaptive Boosting,中文名称叫做自适应提升算法

- 给每个样本分配权重,均为$w_i=\frac{1}{n}$;其中n为样本数量
- 训练一个“弱”模型,通常情况下是决策树DT
- 对于每个目标:
- 如果预测错误,加大权重,w上涨
- 如果预测正确,降低权重,w下降
- 再训练一个新的弱模型,其中权重较大的样本分配较高的优先权
- 重复步骤3和4;直到全部样本被完美预测,或者训练出当前规模的决策树
调整R方

在这里介绍下$R^2$和$\hat R^2$,参考:https://www.jiqizhixin.com/graph/technologies/5155d24b-5ab9-4ce0-8c2c-a3a4c4f8722c
决定系数(英语:coefficient of determination,记为R2或r2)在统计学中用于度量因变量的变异中可由自变量解释部分所占的比例,以此来判断统计模型的解释力。
假设一数据集有$ y_1,…y_i…,y_n$ 共n个观察值(实际值),对应的模型预测值分别为$f_1,…,f_n$。那么我们定义残差:
$e_i = y_i − f_i$
平均观察值为:
$$\bar{y}=\frac{1}{n} \sum_{i=1}^{n} y_{i}$$
总的误差平方和TSS:给出了y的变化总量
$$TSS=\sum_{i}\left(y_{i}-\bar{y}\right)^{2}$$
回归平方和:
$$S S_{\text {reg }}=\sum_{i}\left(f_{i}-\bar{y}\right)^{2}$$
残差平方和RSS:RSS给出了实际点到回归线距离的总平方。残差,我们可以说是回归线没有捕捉到的距离。因此,RSS作为一个整体给了我们目标变量中没有被我们模型解释的变化。(实际值和模型预测值的差异,没有被我们捕捉到)
$$RSS=\sum_{i}n\left(y_{i}-f_{i}\right){2}=\sum_{i}^n e_{i}^{2}$$
现在,如果TSS给出Y的总变化量,RSS是未被解释的变化量,那么TSS-RSS给出了y的变化,并且这部分变化是被我们的模型解释的!我们可以简单地再除以TSS,得到由模型解释的y中的变化比例。
那么,我们定义R的变化统计量$R^2$为:
$$R^{2}=\frac{TSS-RSS}{TSS} = 1-\frac{RSS}{TSS}$$
很显然,RSS和R方是负相关的。
调整R方考虑了用于预测目标变量的自变量数量:
$$\bar{R}{2}=1-\left(1-R{2}\right) \frac{n-1}{n-p-1}$$
- n表示数据集中的数据点数量
- p表示自变量的个数
- R代表模型确定的R方值
Agglomerative clustering-层次聚类
- 所有的观察对象先以自己为群组
- 将满足特定准则的对象聚集在一起
- 重复上面的过程,群组不断增大,直到某个端点的位置饱和

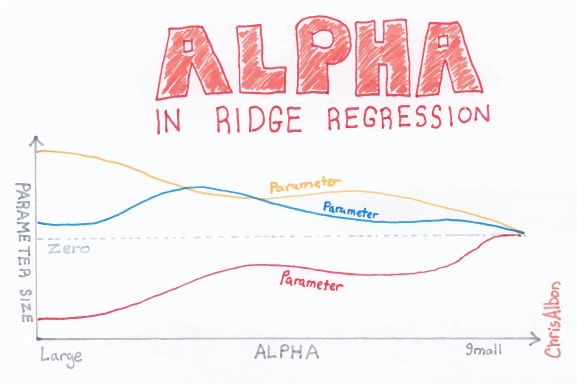
ALPHA
岭回归通过对系数的大小施加惩罚来解决普通最小二乘法的一些问题。 ridge coefficients ( 岭系数 ) 最小化一个带罚项的残差平方和:
$$\min {w}|X w-y|{2}{2}+\alpha|w|_{2}{2}$$
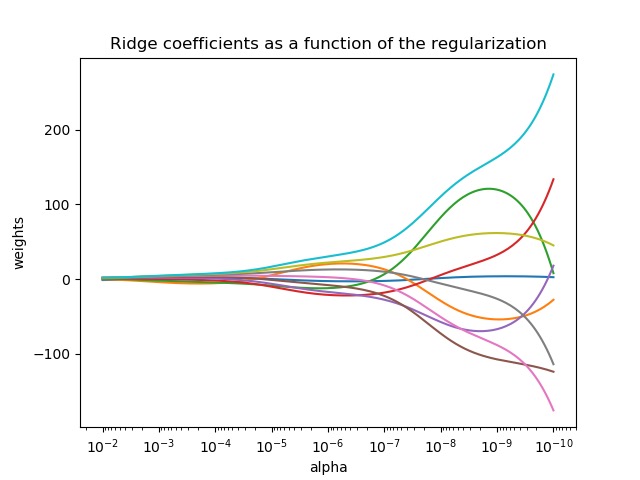
参考资料
https://www.datacamp.com/tutorial/tutorial-lasso-ridge-regression
https://blog.csdn.net/guangyacyb/article/details/86344169
AVOID over-fitting
如何避免过拟合?
- 简化模型
- 交叉验证
- 正则化
- 获取更多数据
- 集成学习

