
kaggle离群点分析
本文是针对kaggle上面一份关于数据离群点的分析,主要是介绍如何从数据中快速确定离群点outlier
原文地址:https://www.kaggle.com/code/nareshbhat/outlier-the-silent-killer
原文标题:Outlier!!! The Silent Killer

什么是离群点
Outlier is an observation that is numerically distant from the rest of the data or in a simple word it is the value which is out of the range.let’s take an example to check what happens to a data set with and data set without outliers.
简答地说:离群值就是和正常值相差甚远的值。
看一个例子:在下面例子的数据中400就是一个离群点。
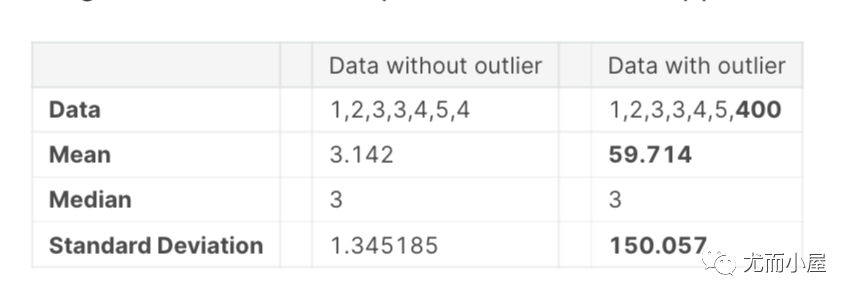
Outlier is a commonly used terminology by analysts and data scientists as it needs close attention else it can result in wildly wrong estimations. Simply speaking, Outlier is an observation that appears far away and diverges from an overall pattern in a sample.
离群值是分析师和数据科学家常用术语,因为它需要密切关注,否则可能会导致严重错误的估计。简单来说,离群值是一种观察结果,它看起来很远并且偏离了样本中的整体模式。
离群值如何产生?
- Data Entry Errors:- Human errors such as errors caused during data collection, recording, or entry can cause outliers in data.
- Measurement Error:- It is the most common source of outliers. This is caused when the measurement instrument used turns out to be faulty.
- Natural Outlier:- When an outlier is not artificial (due to error), it is a natural outlier. Most of real world data belong to this category.
- 数据输入错误:- 人为错误,例如在数据收集、记录或输入过程中造成的错误,可能会导致数据出现异常值。
- 测量误差:- 这是异常值的最常见来源。这是由于使用的测量仪器出现故障造成的。
- 自然异常值:- 当异常值不是人为的(由于错误)时,它就是自然异常值。大多数现实世界的数据都属于这一类。
离群点类型
有两种类型:基于单变量和多变量的类型。上面的例子就是基于单变量,当我们查看单个变量的分布时,可以找到这些异常值。多变量异常值是 n 维空间中的异常值。
确定离群点方法
- Hypothesis Testing - 假设检验
- Z-score method-Z-score法
- Robust Z-score-稳健Z分数
- I.Q.R method-I.Q.R方法
- Winsorization method(Percentile Capping)-Winsorization方法
- DBSCAN Clustering-DBSCAN聚类
- Isolation Forest-孤立森林
- Visualizing the data-可视化数据
假设检验-格鲁布斯检验方法
基于格鲁布斯检验法:
资料1:https://zhuanlan.zhihu.com/p/482006257
资料2:https://blog.csdn.net/sunshihua12829/article/details/49047087

1 | # 忽略警告 |
1 | import numpy as np |
Grubbs Calculated Value: 1.4274928542926593
Grubbs Critical Value: 1.887145117792422
无离群点
Grubbs Calculated Value: 2.2765147221587774
Grubbs Critical Value: 2.019968507680656
存在离群点
Z-SCORE METHOD
参考1:https://zhuanlan.zhihu.com/p/69074703
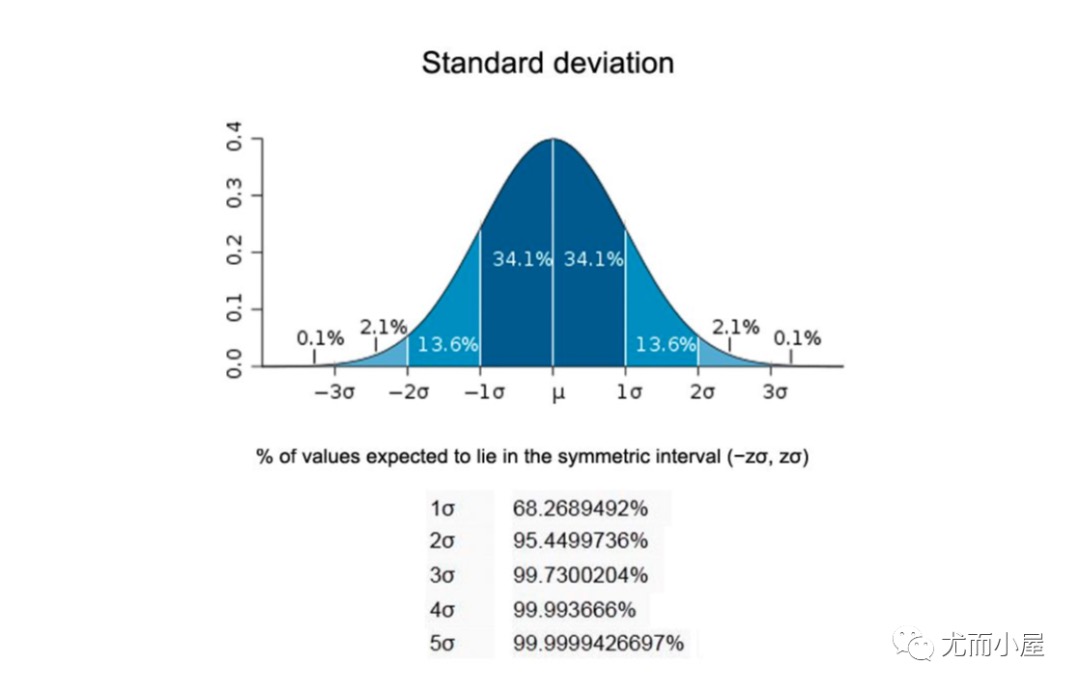
Z-score值的计算:

$$Z_{score} = \frac{X-Mean} {StandarDeviation}$$
1 | import pandas as pd |
Outliers: [50271, 159000, 215245, 164660, 53107, 70761, 53227, 46589, 115149, 53504, 45600, 63887, 57200]
ROBUST Z-SCORE
It is also called as Median absolute deviation method. It is similar to Z-score method with some changes in parameters. Since mean and standard deviations are heavily influenced by outliers, alter to this parameters we use median and absolute deviation from median.
它也被称为中值绝对偏差法。它类似于 Z-score 方法,只是参数有所变化。由于均值和标准差受异常值的影响很大,因此我们使用中位数和中位数的绝对偏差来更改此参数。
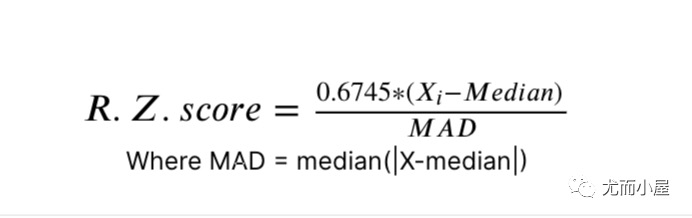
1 | import pandas as pd |
Outliers: [50271, 31770, 22950, 25419, 159000, 39104, 215245, 164660, 53107, 34650, 70761, 53227, 40094, 32668, 25095, 46589, 26178, 115149, 53504, 28698, 45600, 25286, 27650, 24090, 25000, 29959, 23257, 35760, 35133, 32463, 24682, 23595, 36500, 63887, 25339, 57200, 26142]
IQR METHOD
在这种使用四分位数间距 (IQR) 的方法中,我们检测异常值。 IQR 告诉我们数据集中的变化。任何超出 -1.5 x IQR 到 1.5 x IQR 范围的值都被视为异常值。
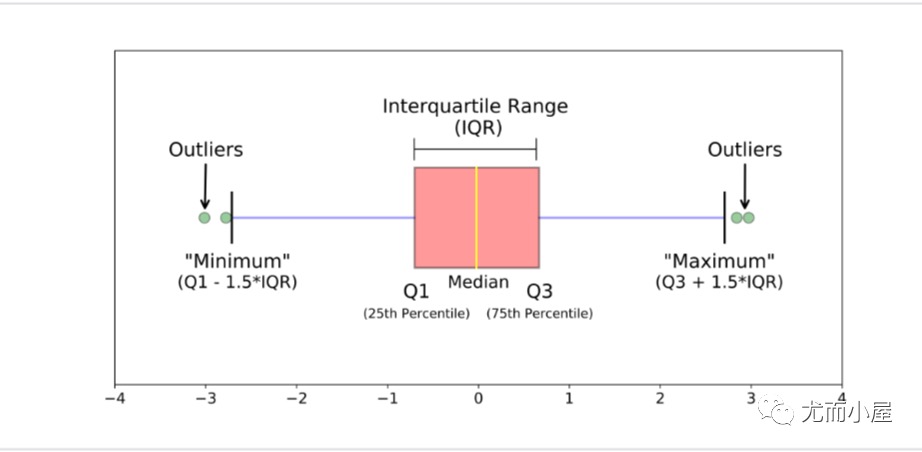
- Q1 表示数据的第一个四分位数/第 25 个百分位数。
- Q2 表示数据的第二个四分位数/中位数/第 50 个百分位数。
- Q3 表示数据的第 3 个四分位数/第 75 个百分位数。
- (Q1–1.5IQR) 代表数据集中的最小值,(Q3+1.5IQR) 代表数据集中的最大值。
1 | import pandas as pd |
Outliers: [50271, 19900, 21000, 21453, 19378, 31770, 22950, 25419, 159000, 19296, 39104, 19138, 18386, 215245, 164660, 20431, 18800, 53107, 34650, 22420, 21750, 70761, 53227, 40094, 32668, 21872, 21780, 25095, 46589, 20896, 18450, 21535, 26178, 115149, 21695, 53504, 21384, 28698, 45600, 17920, 25286, 27650, 24090, 25000, 1300, 21286, 1477, 21750, 29959, 18000, 23257, 17755, 35760, 18030, 35133, 32463, 18890, 24682, 23595, 17871, 36500, 63887, 20781, 25339, 57200, 20544, 19690, 21930, 26142]
缩尾处理-WINSORIZATION METHOD(PERCENTILE CAPPING)
这种方法类似于 IQR 方法。如果一个值超过第 99 个百分位数的值并且低于给定值的第一个百分位数,则将被视为异常值。
1 | import pandas as pd |
Outliers: [263.0, 263.0, 512.3292, 262.375, 263.0, 263.0, 512.3292, 512.3292, 262.375]
聚类-DBSCAN(基于密度的应用噪声空间聚类)
DBSCAN 是一种基于密度的聚类算法,它将数据集划分为高密度区域的子组,并将高密度区域聚类识别为异常值
1 | import pandas as pd |
0 705
2 50
4 36
-1 32
6 15
1 12
7 8
5 7
8 7
9 7
3 6
10 6
Name: cluster, dtype: int64
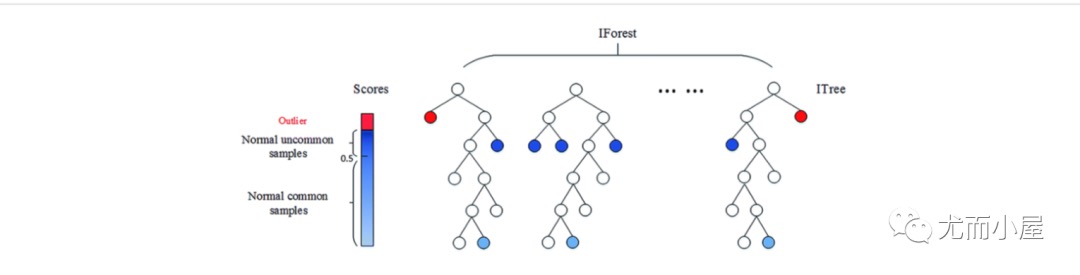
孤立森林-ISOLATION FOREST
它是一种属于集成决策树家族的聚类算法,在原理上类似于随机森林
1 | from sklearn.ensemble import IsolationForest |
1 706
-1 185
Name: cluster, dtype: int64
基于数据可视化
通过箱型图、散点图、直方图、两两分布图、QQ图等将数据进行可视化,通过观察来找到离群点
1 | import pandas as pd |
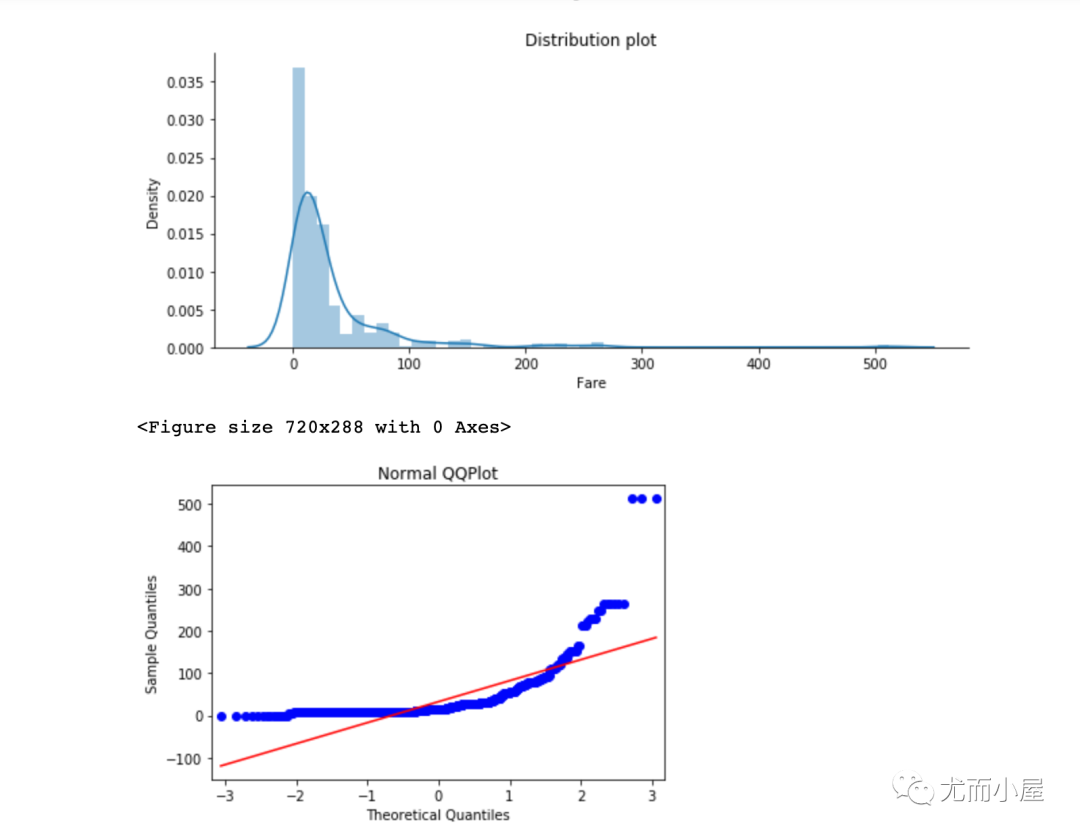
异常值处理
上面介绍的内容是如何发现数据中的离群点。在找到离群点后,如何处理?
处理1:删除离群点
1 | import pandas as pd |
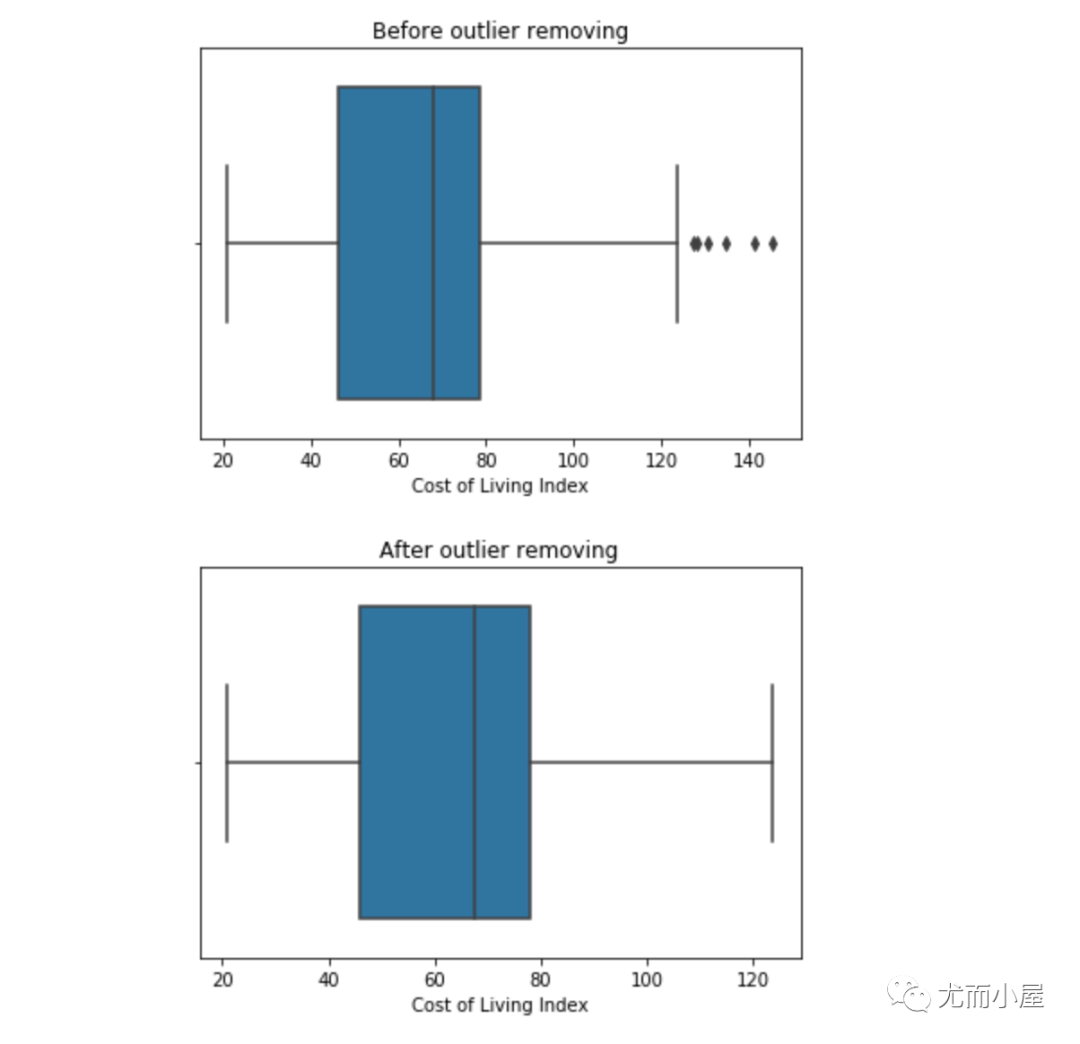
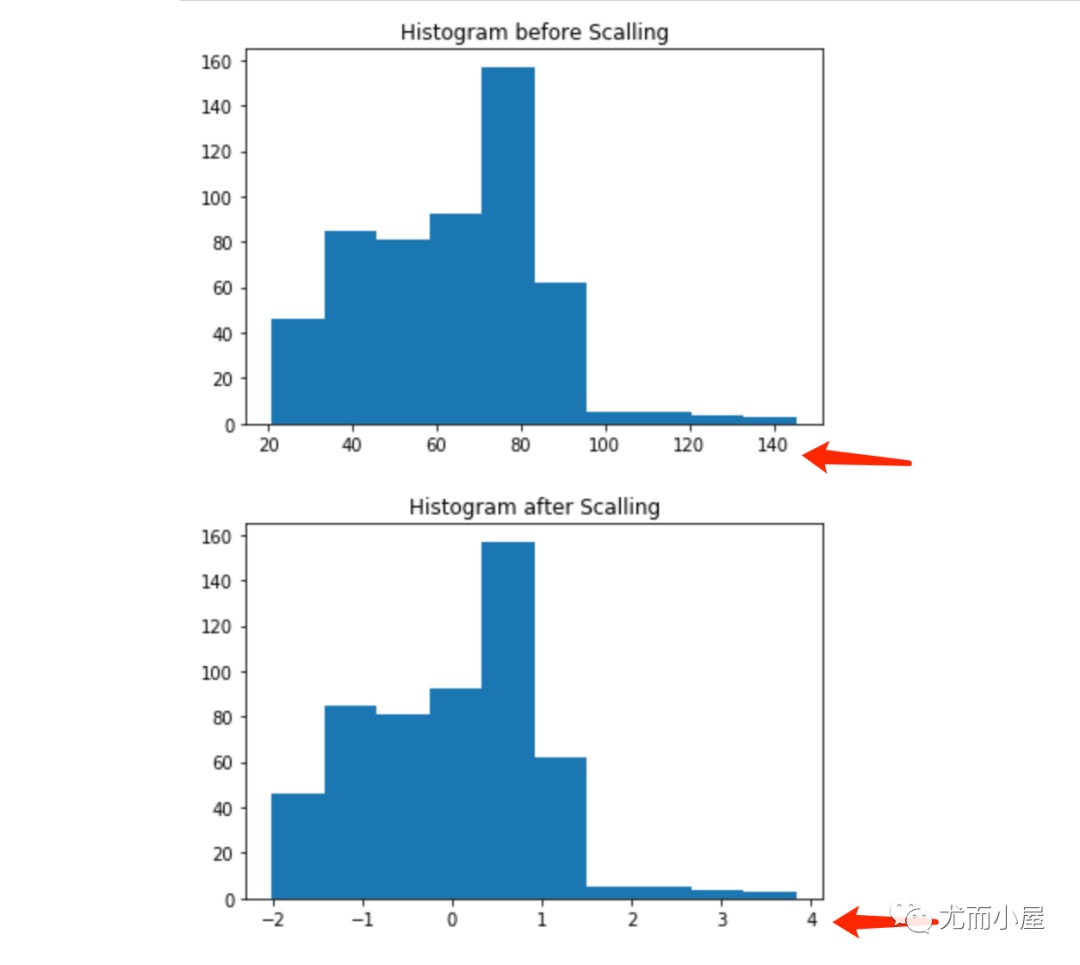
处理2:数据转换
介绍4种数据转换的方法:
- 尺度缩放:Scalling
- 对数变换:Log transformation
- 立方根归一化:Cube Root Normalization
- Box-Cox转换:Box-Cox transformation
1 | # 尺度缩放 |
1 | # 2、基于对数变换 |

1 | # 3、基于立方根转换 |
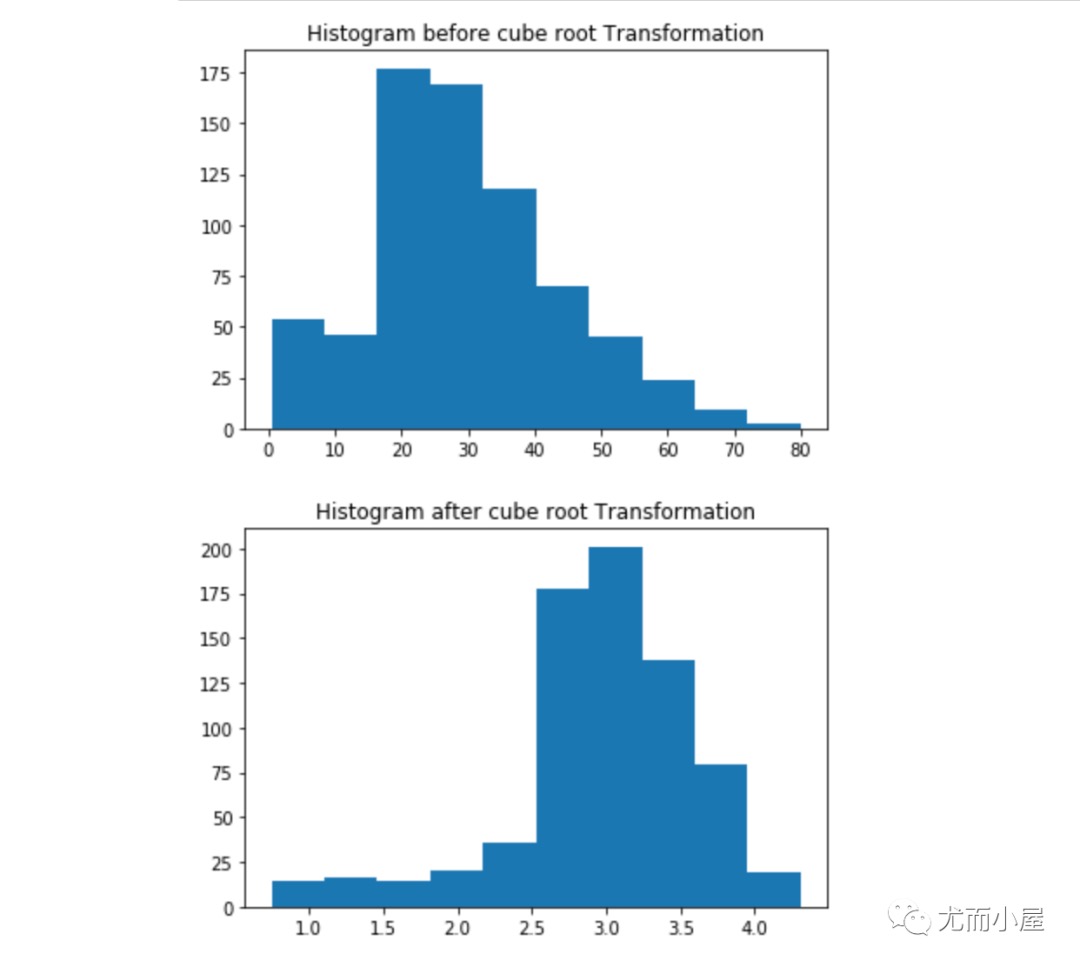
1 | # 4、Box-Cox转换 |
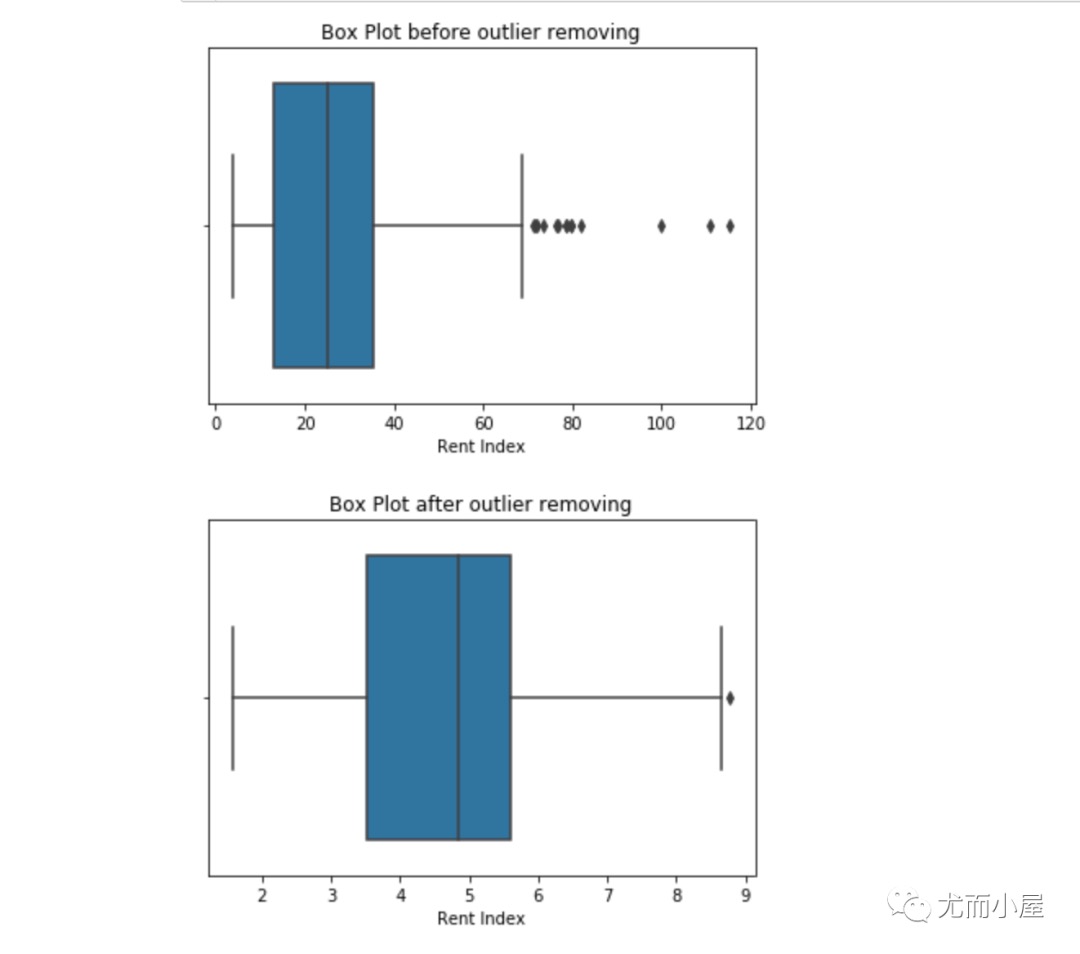
处理3:数值插补Imputation
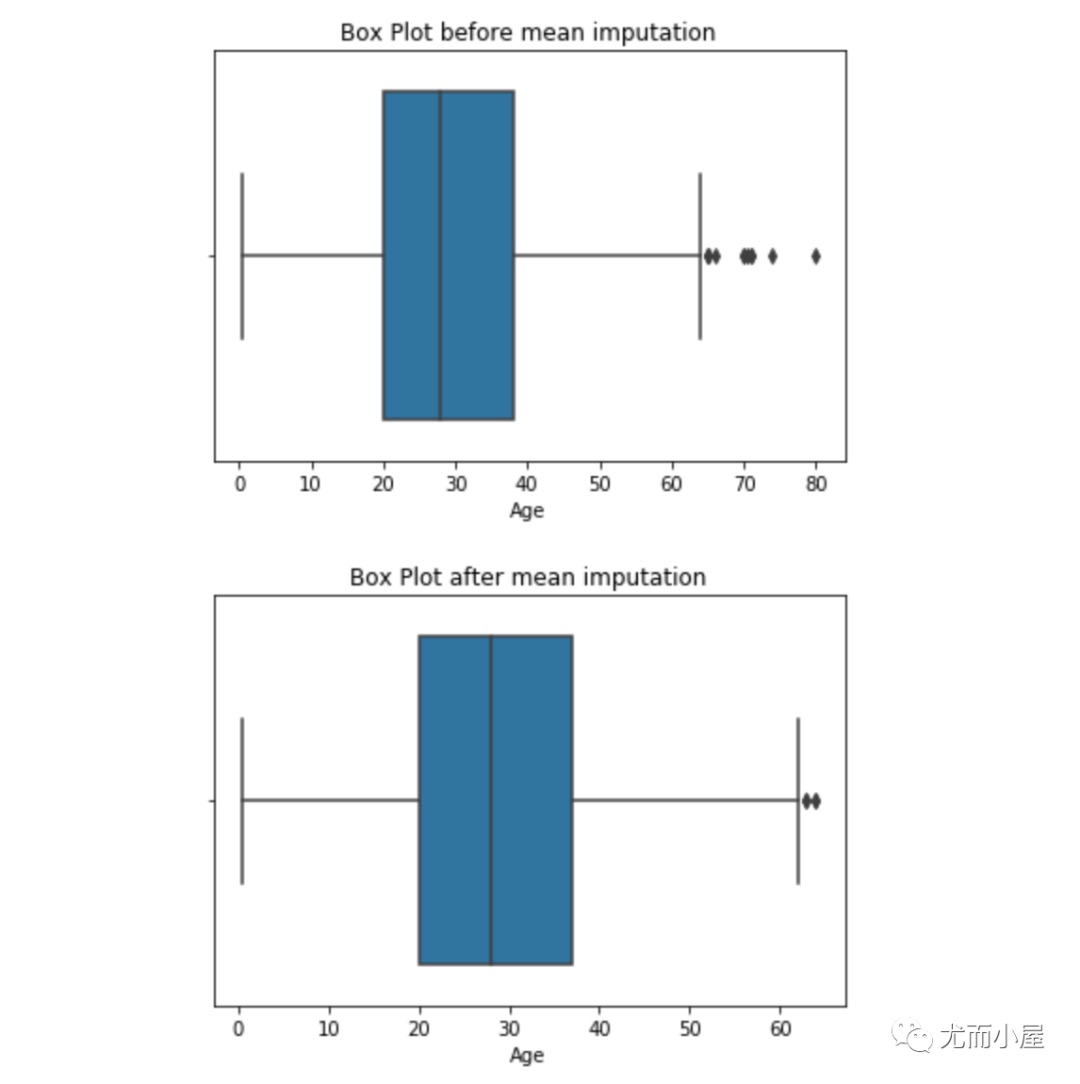
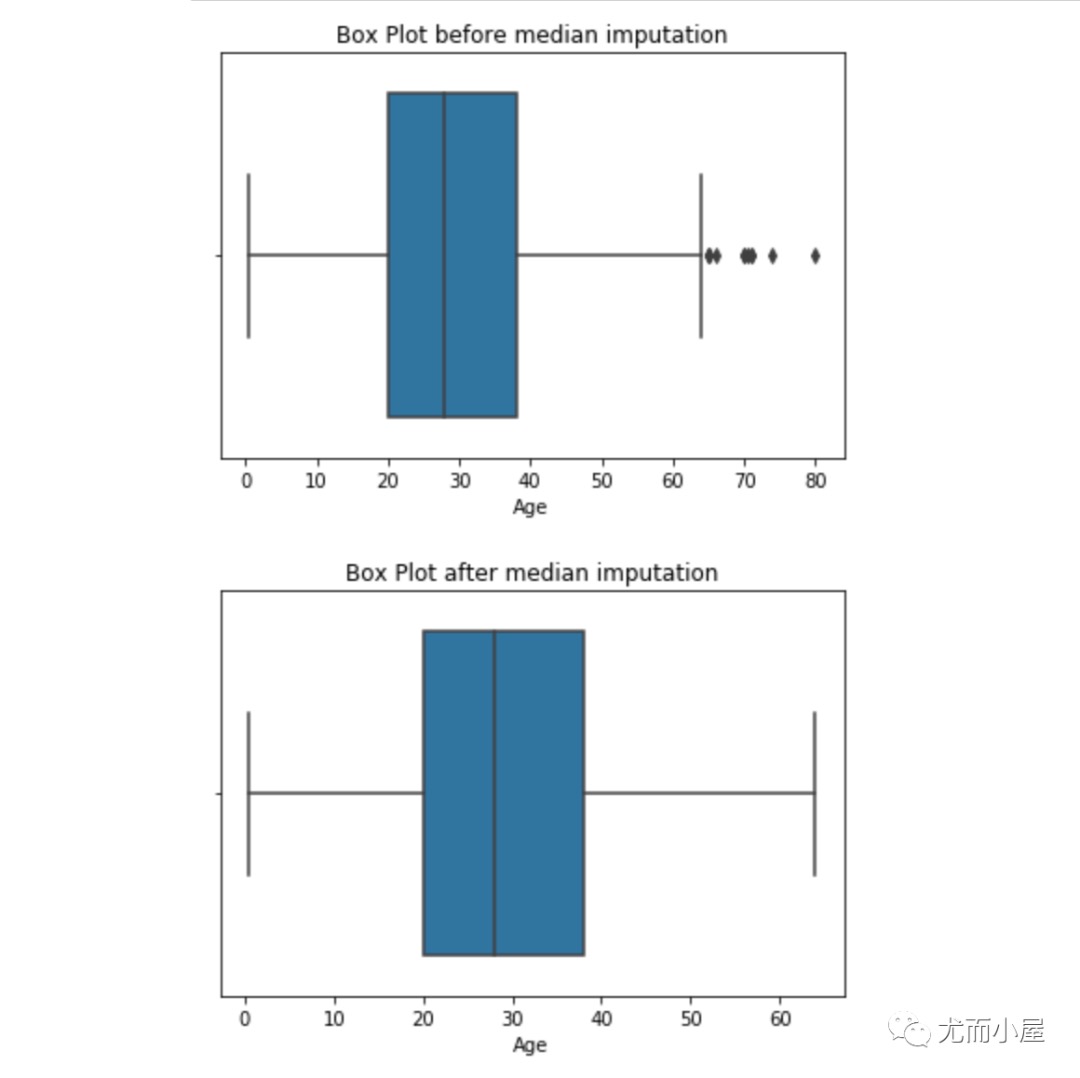
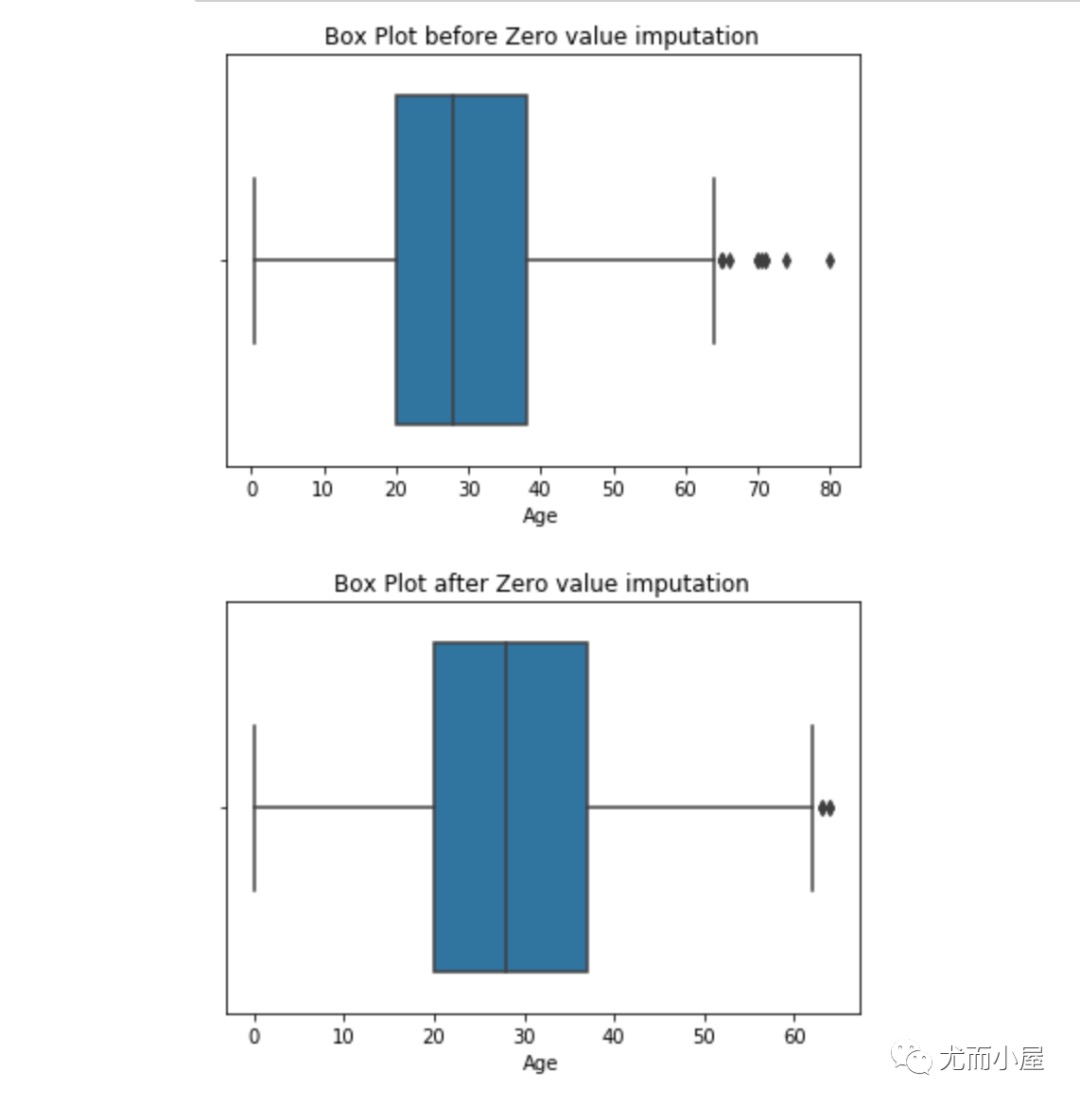
与缺失值的插补一样,我们也可以插补异常值。我们可以在此方法中使用均值、中值、零值。一般在这里使用中位数是最合适的,因为它不受异常值的影响。
1 | # 基于均值插补 |
1 | # 基于中位数插补 |
1 | # 基于零值插补 |
处理4:离群点单独处理
如果存在大量的异常值并且数据集很小,在统计模型中我们应该将它们分开处理。一种方法是将离群点和非离群点视为两个不同的组,并为两个组构建单独的模型,然后组合输出。
总结
- 当数据有异常值或偏斜时,中位数是数据集中趋势的最佳度量。
- Winsorization Method 或 Percentile Capping 是其他方法中更好的异常值检测技术。
- 中位数插补是最好的离群值插补方法。
